The Heart of Execution: The JavaScript Engine
At the center of every modern web browser lies a sophisticated piece of software responsible for breathing life into the dynamic, interactive experiences that define the web: the JavaScript engine. This engine is the core component that interprets and executes JavaScript code. Its primary mandate is to translate the high-level, human-readable code written by developers into low-level machine instructions that a computer’s central processing unit (CPU) can understand and execute.1 In essence, it serves as a critical intermediary, abstracting the complexities of the underlying hardware and providing a consistent execution environment for scripts, regardless of the operating system or device.2
While the JavaScript engine is most famously associated with web browsers, its design as a standalone component has allowed it to be embedded in a wide array of other environments. Server-side runtimes like Node.js and Deno, for instance, are built around Google’s V8 engine, enabling JavaScript to be used for building scalable network applications. Even databases such as MongoDB and CouchDB leverage JavaScript engines for querying and server-side logic.3 This versatility underscores a fundamental architectural point: the engine itself is a pure language executor, independent of the browser environment that hosts it. Every major browser vendor develops its own engine, with the most prominent being Google’s V8 in Chrome and Microsoft Edge, Mozilla’s SpiderMonkey in Firefox, and Apple’s JavaScriptCore in Safari.5
Quick Review
1. The JavaScript Engine and its Core Components
A JavaScript engine is a specialized program designed to interpret and execute JavaScript code. Every major web browser includes its own JS engine.
- V8: Google’s open-source engine, used in Google Chrome, Microsoft Edge, and the Node.js runtime.
- SpiderMonkey: Mozilla’s engine, powering Firefox.
- JavaScriptCore: Apple’s engine, used in Safari.
All engines, despite their differences, are built around two fundamental components:
- Memory Heap: This is a large, unstructured region of memory where the engine stores all the objects, functions, and other complex data structures that are created during the execution of the code. Memory allocation and deallocation happen in this space.
- Call Stack: This is a Last-In, First-Out (LIFO) data structure that tracks the execution of functions. Each function call creates a new “stack frame” containing the function’s arguments and local variables. This frame is pushed onto the top of the stack. When the function finishes, its frame is popped off the stack.
2. Synchronous Execution and the Call Stack
By its nature, JavaScript is single-threaded, meaning it can only execute one command at a time. This synchronous execution is managed by the Call Stack.
- Global Execution Context: When a script first runs, the engine creates a Global Execution Context and pushes it to the bottom of the Call Stack. This context represents the global scope of the script.
- Function Calls: When a function is invoked, a new Function Execution Context is created for it and pushed onto the top of the stack.
- Execution: The engine always executes the function corresponding to the frame at the top of the stack.
- Returning: When a function completes (i.e., hits a
returnstatement or the end of its code block), its execution context is popped off the stack, and control returns to the context below it.
A Stack Overflow error occurs when the Call Stack grows beyond its maximum limit, typically caused by a recursive function that never terminates.
3. The Browser Runtime Environment & Web APIs
The JavaScript engine provides the core capabilities of the language, but the browser provides a much richer environment for it to run in. This is the JavaScript Runtime Environment. It extends the engine with a host of Web APIs that allow JavaScript to interact with the browser and the outside world.
These APIs are not part of the core JavaScript language itself but are provided by the browser. Key examples include:
- Document Object Model (DOM) API: Allows JS to interact with the HTML structure of the page, enabling dynamic content updates, style changes, and event handling.
setTimeoutandsetInterval: Allow scheduling code to run after a specified delay or at regular intervals.- Fetch API: Provides a modern interface for making HTTP network requests to servers to retrieve data or resources.
- Console API: Provides access to the browser’s debugging console (e.g.,
console.log()).
4. Handling Asynchronous JavaScript: The Event Loop Model
The single-threaded nature of JavaScript would be a major limitation if long-running tasks (like network requests or timers) blocked the Call Stack. This would freeze the browser UI. To solve this, the runtime environment uses an asynchronous, non-blocking model.
This model involves a few more components besides the engine’s Call Stack:
- Callback Queue (or Task Queue): A First-In, First-Out (FIFO) queue that holds callback functions from macrotasks. Macrotasks include events like
setTimeout,setInterval, and I/O operations. - Microtask Queue: A separate FIFO queue that holds callbacks from microtasks, primarily promises (e.g.,
.then(),.catch(),.finally()) andqueueMicrotask(). This queue has a higher priority than the Callback Queue. - The Event Loop: This is the heart of the asynchronous model. It’s a constantly running process with a simple but critical job: to monitor both the Call Stack and the queues.
The asynchronous flow works as follows:
- When an asynchronous function (like
fetch(url)) is called, the engine sends the operation to the relevant Web API and immediately moves on, keeping the Call Stack clear. - The Web API handles the operation in the background. Once it’s complete, it places the associated callback function into either the Microtask Queue (for promises) or the Callback Queue.
- The Event Loop continuously checks: “Is the Call Stack empty?”
- If the Call Stack is empty, the Event Loop first checks the Microtask Queue. If it contains any tasks, the loop takes the first one, pushes it onto the Call Stack, and executes it. It will continue to process the entire Microtask Queue until it is empty.
- Only after the Microtask Queue is empty will the Event Loop check the Callback Queue. If it contains tasks, the loop takes the oldest one, pushes it to the Call Stack, and executes it.
This model ensures that the Call Stack remains free to handle user interactions and other short tasks, preventing the page from becoming unresponsive.
5. Code to Execution: Parsing and JIT Compilation
Before code can be executed, it must be processed by the engine. Modern engines use a sophisticated pipeline involving Just-In-Time (JIT) compilation.
- Parsing: The engine’s parser reads the source code and breaks it down into tokens. These tokens are then used to build an Abstract Syntax Tree (AST), which is a tree-like representation of the code’s structure.
- Interpretation & Compilation: V8, for example, uses an interpreter called Ignition that takes the AST and generates bytecode. This bytecode is a lower-level, intermediate representation of the code.
- Optimization: While the bytecode is running, Ignition collects profiling data about which parts of the code are executed frequently (these are called “hot” functions). This data is passed to an optimizing compiler called TurboFan.
- JIT Compilation: TurboFan takes the “hot” bytecode and profiling data and compiles it directly into highly optimized machine code. It makes speculative optimizations based on the data. If an assumption turns out to be wrong (e.g., a variable changes type), it de-optimizes and falls back to the bytecode.
This combination provides the best of both worlds: fast startup times from the interpreter and high performance for frequently executed code from the JIT compiler.
6. Interaction with the Rendering Engine
When JavaScript modifies the page via the DOM API, it directly interacts with the browser’s rendering engine (e.g., Blink in Chrome, Gecko in Firefox). This can trigger expensive operations on the Critical Rendering Path.
- DOM Manipulation: Code like
document.getElementById('myEl').style.width = '100px';changes the DOM. - Layout (Reflow): If the change affects the geometry of an element (its size, position, or shape), the browser must invalidate the layout and re-calculate the positions and dimensions of all affected elements. This process is called Layout or Reflow. Changing properties like
width,height,margin, orfont-sizewill trigger a reflow. - Paint (Repaint): After the layout is calculated, the browser must redraw the pixels of the affected elements to the screen. This is called Paint or Repaint. Changing properties that don’t affect layout, like
color,background-color, orbox-shadow, will only trigger a paint.
Frequent and unnecessary reflows and repaints are a common cause of poor performance and janky animations. Best practices include batching DOM updates and using CSS transforms and opacity, which are often handled more efficiently by the rendering engine.
7. Memory Management and Garbage Collection
JavaScript uses automatic memory management to free developers from manual memory allocation and deallocation.
- Allocation: When you declare a variable or create an object (
let user = {name: 'Alex'}), memory is automatically allocated on the Memory Heap. - Garbage Collection: A background process called the Garbage Collector (GC) is responsible for freeing up memory that is no longer needed. The primary challenge for the GC is to determine which memory is “no longer needed.” Most modern engines use an algorithm called Mark-and-Sweep.
The Mark-and-Sweep Algorithm works as follows:
- The GC starts from a set of “roots” (global objects and currently active function contexts).
- It traverses all objects reachable from these roots and “marks” them as reachable (in use).
- Finally, it “sweeps” through the entire Memory Heap and deallocates any memory that was not marked, as it is considered unreachable and therefore garbage. This algorithm effectively handles “cyclic references” (where object A references B, and B references A), which older reference-counting algorithms could not.
Core Concepts: The Engine’s Mandate
The primary responsibility of any JavaScript engine is to parse and execute code. Modern engines accomplish this through a process known as just-in-time (JIT) compilation, a hybrid approach that combines the speed of compilation with the flexibility of interpretation to deliver high performance.1 The engine’s operation is governed by the ECMAScript specification, the standard that defines the JavaScript language, its syntax, and its core objects and behaviors.5
To manage the execution of code, every JavaScript engine is fundamentally composed of two key components: a Memory Heap and a Call Stack.2 These structures form the foundational memory model upon which all JavaScript execution is built. The engine acts as the manager of these resources, allocating memory for variables and functions, tracking the execution of code, and cleaning up memory that is no longer needed. This intricate management allows developers to write code without concerning themselves with the low-level details of memory allocation and deallocation, a hallmark of high-level, garbage-collected languages.8
The Memory Model: A Deep Dive into the Heap and Call Stack
The logical separation of memory into a heap and a stack is a classic computer science pattern that JavaScript engines employ to efficiently manage the state of a running program. Each structure serves a distinct purpose, and their interaction is central to the engine’s operation.
The Memory Heap
The Memory Heap is a large, unstructured region of memory where the engine stores all dynamically allocated objects.2 This includes JavaScript objects, arrays, and functions. When a developer declares a variable that holds an object, the engine allocates a block of memory in the heap to store that object’s data. The variable itself does not contain the object; instead, it holds a reference, or a pointer, to the object’s location in the heap.9 This is why objects in JavaScript are referred to as “reference types.”
For example, the statement let user = { name: ‘Alice’ }; instructs the engine to allocate memory in the heap for an object with a name property. The user variable, which is managed on the stack, then stores the memory address of this newly created object.9 Because the heap is designed for dynamic allocation and can grow or shrink as needed, it is inherently more complex to manage than the stack. Consequently, accessing memory in the heap is generally slower than accessing memory on the stack.12 The engine employs a sophisticated process called garbage collection to automatically identify and free up memory in the heap that is no longer in use, which will be discussed in a later section.
The Call Stack
In contrast to the heap, the Call Stack is a highly structured, ordered region of memory that operates on a Last-In, First-Out (LIFO) principle.2 Its primary purpose is to keep track of function execution. When a script begins to run, the engine creates a global execution context and places it at the bottom of the call stack. Every time a function is invoked, the engine creates a new “stack frame” for that function and pushes it onto the top of the stack.13
This stack frame, also known as an Execution Context, is a data structure that contains essential information for the function’s execution, including its parameters, local variables, and the return address—the point in the code to which execution should return after the function completes.13 The function at the very top of the stack is the one currently being executed. Once a function finishes its work and returns, its corresponding stack frame is popped off the stack, and control is passed back to the function below it.9 This continuous push-and-pop mechanism allows the engine to manage nested function calls and maintain the correct order of execution.
Execution Contexts
The concept of an Execution Context is the fundamental unit of execution within the JavaScript engine. There are two primary types of execution contexts:
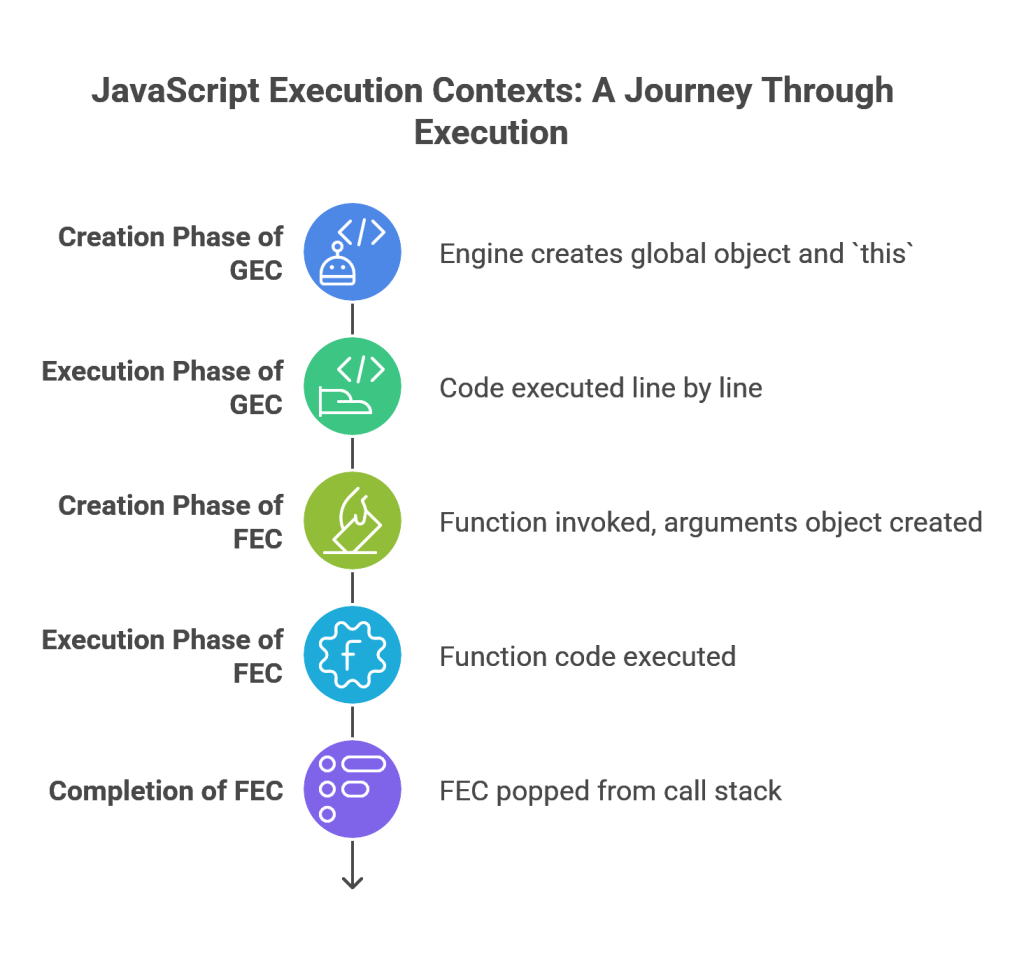
- Global Execution Context (GEC): This is the base context created when the JavaScript engine first starts interpreting a script. It is created only once and represents the global scope of the program.15 The GEC’s creation involves two phases. In the
Creation Phase, the engine creates a global object (window in browsers, global in Node.js) and a special variable called this, which points to the global object.17 It also scans the code for all variable (
var) and function declarations, allocates memory for them, and initializes the variables with a default value of undefined. This process is known as hoisting.17 In the subsequent
Execution Phase, the engine executes the code line by line, assigning the actual values to variables and invoking functions.17 - Function Execution Context (FEC): A new FEC is created every single time a function is invoked.17 It follows the same two-phase process as the GEC. During its Creation Phase, it creates an
arguments object (containing all arguments passed to the function), a this variable (whose value depends on how the function was called), and hoists any local variable and function declarations.15 During the Execution Phase, the function’s code is executed. When the function completes, its FEC is popped from the call stack.17
The single-threaded nature of JavaScript means there is only one Call Stack, and therefore only one task can be executed at any given moment.9 This synchronous, one-at-a-time execution model is a defining characteristic of the language.
Stack Overflow
Because the Call Stack has a finite size, there is a limit to how many stack frames it can hold. A Stack Overflow error occurs when this limit is exceeded. This condition is most commonly caused by an unterminated recursive function—a function that calls itself without a proper base case to stop the recursion. With each recursive call, a new stack frame is pushed onto the stack. If the recursion never ends, the stack will eventually run out of space, causing the program to crash.9 For example, the function
function infinite() { infinite(); } would immediately cause a stack overflow upon being called.
Code Example: Call Stack LIFO Behavior
To illustrate the LIFO behavior of the Call Stack, consider the following sequence of nested function calls 22
function thirdFunction() {
console.log("Executing thirdFunction");
}
function secondFunction() {
console.log("Entering secondFunction");
thirdFunction();
console.log("Exiting secondFunction");
}
function firstFunction() {
console.log("Entering firstFunction");
secondFunction();
console.log("Exiting firstFunction");
}
firstFunction();
The execution flow managed by the Call Stack proceeds as follows:
- The script begins, and the Global Execution Context is pushed onto the stack.
- firstFunction() is invoked. A new stack frame for firstFunction is created and pushed onto the top of the stack. Entering firstFunction is logged.
- Inside firstFunction, secondFunction() is invoked. A stack frame for secondFunction is pushed on top of firstFunction’s frame. Entering secondFunction is logged.
- Inside secondFunction, thirdFunction() is invoked. A stack frame for thirdFunction is pushed on top of secondFunction’s frame.
- thirdFunction is now at the top of the stack. It executes its code, logging Executing thirdFunction.
- thirdFunction completes. Its stack frame is popped from the stack (Last-In, First-Out).
- Execution returns to secondFunction, which was the next item on the stack. It continues from where it left off, logging Exiting secondFunction.
- secondFunction completes. Its stack frame is popped from the stack.
- Execution returns to firstFunction. It continues, logging Exiting firstFunction.
- firstFunction completes and is popped. The stack is now empty except for the GEC. The script finishes.
This step-by-step process demonstrates how the Call Stack meticulously manages the flow of control in a synchronous JavaScript program. This fundamental architecture—a single, synchronous Call Stack—is the primary reason that the broader browser environment needed to develop a sophisticated asynchronous model. A long-running task, such as a network request, cannot be executed directly on the Call Stack without blocking the entire program and freezing the user interface. This limitation led to the creation of Web APIs and the Event Loop, which work in concert with the engine to handle such tasks off the main thread, forming the basis of JavaScript’s non-blocking concurrency model.
From Source Code to Machine Code: The Modern Compilation Pipeline
The process by which a JavaScript engine transforms human-readable source code into executable machine code is a multi-stage pipeline that has evolved significantly over time. Early engines were simple interpreters, but the demands of complex web applications necessitated a more performant approach, leading to the development of modern Just-In-Time (JIT) compilation pipelines.
Parsing and the Abstract Syntax Tree (AST)
The journey begins with the Parser. When the engine receives a script, the parser’s first job is to perform lexical analysis, breaking the raw string of code into a sequence of atomic pieces called tokens.21 For example, the line
const x = 10; would be tokenized into const, x, =, 10, and ;.
These tokens are then fed into the next stage of the parser, which performs syntactic analysis. It uses the grammar rules of the JavaScript language to build a tree-like data structure known as an Abstract Syntax Tree (AST).2 The AST is a hierarchical representation of the code’s grammatical structure, capturing the relationships between different parts of the program. Each node in the tree represents a construct in the code, such as a variable declaration, a function call, or a loop. During this phase, the parser also checks for syntax errors; if the code is grammatically incorrect, the process halts and an error is thrown.2 The AST is a critical intermediate representation that makes it easier for the subsequent stages of the pipeline to analyze, understand, and transform the code.26
The Role of the Interpreter and Bytecode
Historically, JavaScript was a purely interpreted language, meaning an interpreter would traverse the AST and execute the code line by line.2 While simple, this approach is relatively slow. Modern engines have introduced an intermediate step. After the AST is generated, a baseline compiler or interpreter (like V8’s
Ignition) walks the AST and compiles it into an intermediate representation called bytecode.6
Bytecode is a set of low-level, platform-independent instructions that is more abstract than machine code but much closer to it than the original source code. It is designed to be executed by a virtual machine or interpreter. This step is beneficial because executing bytecode is significantly faster than re-parsing the AST for every execution, and bytecode is often more compact and memory-efficient.24 The engine can now start executing the program quickly by having the interpreter run this bytecode.
Just-In-Time (JIT) Compilation
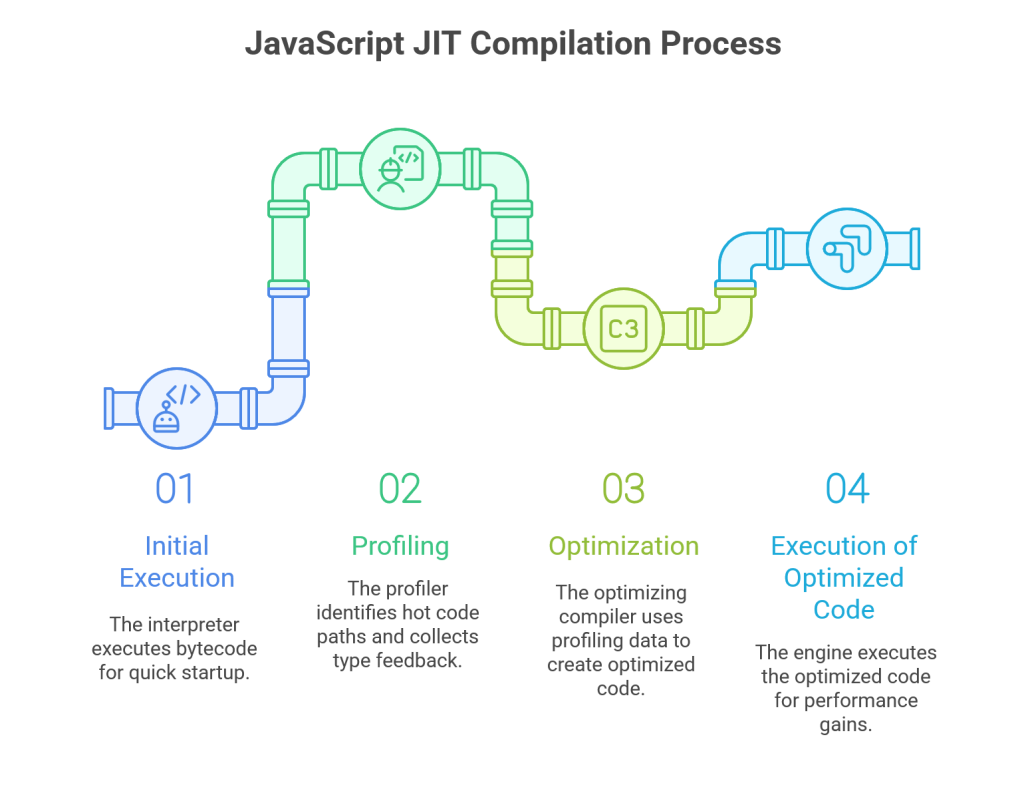
The true power of modern JavaScript engines comes from Just-In-Time (JIT) compilation. This is a hybrid strategy that combines the fast startup of an interpreter with the high runtime performance of a compiler.1 The process works as follows:
- Initial Execution: The engine begins by having its interpreter (e.g., Ignition) execute the bytecode. This allows the code to start running almost immediately, which is crucial for a good user experience on the web.10
- Profiling: While the interpreter is running, a component called the profiler (or monitor) runs in the background. Its job is to observe the code as it executes and gather data. Specifically, it identifies “hot” code paths—functions or loops that are executed frequently.24 The profiler also collects type feedback, noting the types of variables that are passed to functions and used in operations.
- Optimization: When a piece of code is identified as “hot,” the engine sends it, along with the collected profiling data, to an optimizing compiler (like V8’s TurboFan).26 This compiler uses the type information to make speculative optimizations. For example, if it observes that a function is always called with numbers, it can generate highly specialized and efficient machine code that performs arithmetic directly, bypassing the slower, more generic operations required for a dynamically typed language.
- Execution of Optimized Code: The resulting optimized machine code replaces the bytecode for that specific function. The next time the function is called, the engine executes this much faster native code directly, leading to significant performance gains.
Deoptimization
The optimizations made by the JIT compiler are speculative, based on past observations. However, JavaScript is a dynamic language, and the assumptions made during optimization might later be proven incorrect. For instance, a function that was previously only called with numbers might suddenly be called with a string.
When this happens, the optimized machine code is no longer valid. The engine must perform a deoptimization. It discards the now-incorrect optimized code and “bails out,” reverting execution back to the slower, more generic interpreted bytecode, which can handle any type.27 The engine may then re-optimize the function later based on the new type information it has gathered. This ability to optimize and deoptimize on the fly is a crucial trade-off, allowing engines to achieve near-native performance for predictable code while still correctly handling the full dynamic nature of JavaScript.
This evolution from simple interpreters to complex, multi-stage JIT compilation pipelines was not merely an incremental improvement; it was a necessary paradigm shift. The rise of sophisticated web applications like Google Maps and Gmail, which demanded performance far beyond what interpreters could offer, drove this innovation.31 A traditional ahead-of-time (AOT) compiler, as used in languages like C++, was unsuitable for the web, where code is delivered on-demand and there is no explicit “build” step for the user.2 The JIT compiler emerged as the ideal compromise, embodying a core design trade-off: it prioritizes a fast startup via interpretation while intelligently investing the heavy cost of compilation only on the parts of the code where it will yield the greatest performance benefit. This dynamic, tiered approach is the cornerstone of modern JavaScript performance.
A Comparative Analysis of Modern JavaScript Engines
While all modern JavaScript engines share the common goal of executing code efficiently, they achieve this through distinct architectural designs and optimization strategies. The three most influential engines today are Google’s V8, Mozilla’s SpiderMonkey, and Apple’s JavaScriptCore. A comparative analysis reveals a fascinating story of convergent evolution, where different engineering teams, facing the same fundamental challenges, have arrived at remarkably similar solutions, particularly the adoption of multi-tiered compilation pipelines.
Google’s V8 (Chrome, Node.js, Edge)
V8 is arguably the most well-known JavaScript engine, powering not only Google Chrome but also the vast server-side ecosystem of Node.js, as well as other browsers like Microsoft Edge and Brave.31 Written in C++, V8 is renowned for its high-performance JIT compilation and continuous innovation.6
Architecture and Key Components
V8’s modern architecture is a sophisticated, multi-tiered pipeline designed to balance fast startup with peak performance:
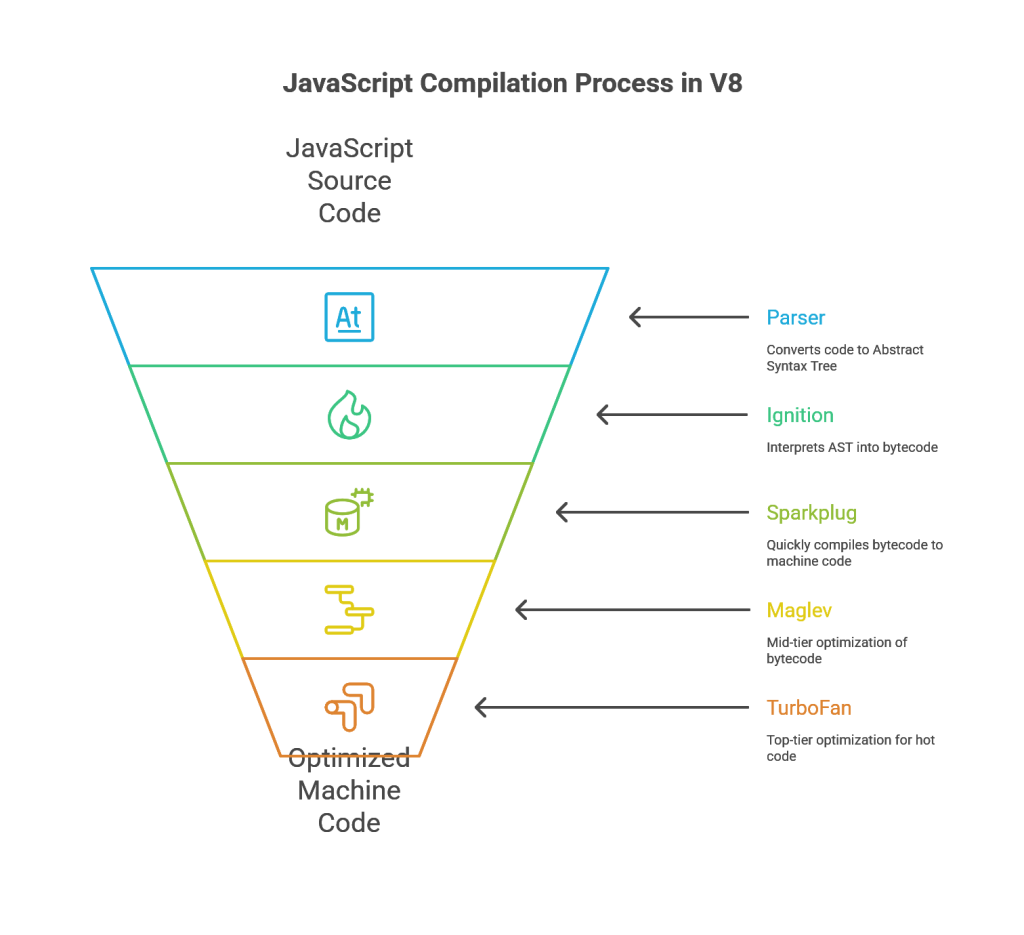
- Parser: The process begins with the parser, which takes the raw JavaScript source code and generates an Abstract Syntax Tree (AST).26
- Ignition (Interpreter): V8’s interpreter, Ignition, plays a central role. It consumes the AST and compiles it into a concise bytecode format. Ignition then executes this bytecode, allowing the script to start running quickly and with a relatively low memory footprint. This bytecode also serves as a stable baseline for the optimizing compilers.26
- Sparkplug: Introduced to bridge the gap between interpretation and full optimization, Sparkplug is a very fast, non-optimizing compiler. It compiles bytecode directly to machine code much faster than the main optimizing compiler, providing a significant performance boost for code that is executed more than a few times but is not yet considered “hot”.31
- Maglev: Another recent addition, Maglev is a mid-tier optimizing compiler. It is faster than TurboFan but produces less optimized code. It targets functions that are frequently executed but not critical enough to warrant the more time-consuming and complex optimizations of the top-tier compiler.31
- TurboFan (Optimizing Compiler): At the top of the hierarchy is TurboFan, V8’s state-of-the-art optimizing compiler. It takes bytecode from Ignition and rich profiling data (type feedback) gathered during execution to generate highly specialized and optimized machine code for the hottest parts of the application.26
Optimization Techniques
V8 employs several key techniques to optimize dynamic JavaScript code:
- Hidden Classes (Maps): To overcome the performance penalty of dynamic property lookups, V8 uses a technique called hidden classes (or Maps internally). When an object is created, V8 creates a hidden class that describes its shape and property layout. Objects that have the same properties added in the same order will share the same hidden class. This allows V8 to access properties using a fixed offset, similar to how statically typed languages work, which is much faster than a dictionary-style lookup.7
- Inline Caching (IC): V8 heavily relies on Inline Caching to speed up repeated operations. An IC is a small stub of code that caches the result of a previous operation. For property access, if an IC sees that the operation is consistently performed on objects with the same hidden class (a monomorphic state), it can reuse the cached information about the property’s memory location. If the operation encounters objects with a few different hidden classes (polymorphic), the IC becomes less efficient. If it encounters too many different shapes (megamorphic), the optimization is abandoned, and the engine falls back to a much slower, generic lookup.7
Mozilla’s SpiderMonkey (Firefox)
As the very first JavaScript engine, created by Brendan Eich in 1995, SpiderMonkey has a long and storied history of evolution.32 Its development path, from a simple interpreter through a series of JIT compilers (TraceMonkey, JägerMonkey, IonMonkey), mirrors the broader industry’s relentless pursuit of performance. The modern SpiderMonkey engine is written in C++ and Rust and features its own advanced, multi-tiered architecture.
Architecture and Key Components
- Parser: SpiderMonkey employs multiple parsers tailored for different tasks. A fast parser can quickly scan for syntax errors without allocating much memory, while a more comprehensive “Full Parser” is used to build the detailed AST required for compilation.33
- Baseline Interpreter: This is the first execution tier. It quickly executes untyped bytecode generated from the AST, ensuring a fast initial startup time for web pages.32
- Baseline JIT: As the code runs, the profiler identifies frequently executed code paths. These are then sent to the Baseline JIT, which compiles the bytecode into machine code. This tier performs simple but effective optimizations, such as polymorphic inline caches, providing a solid performance improvement over the interpreter.32
- IonMonkey (Optimizing JIT): For the hottest code, SpiderMonkey uses IonMonkey, a highly advanced optimizing compiler. It operates on a more traditional compiler model, translating bytecode into an intermediate representation based on Static Single Assignment (SSA) form. This allows it to apply a wide range of powerful optimizations drawn from the world of static compilers, including type specialization, function inlining, loop-invariant code motion, and dead code elimination, resulting in extremely efficient machine code.32
- WarpMonkey (WarpBuilder): The latest enhancement to the pipeline, WarpBuilder (part of the WarpMonkey project) focuses on speeding up the work of IonMonkey itself. It optimizes the process of translating SpiderMonkey’s bytecode into the intermediate representation that IonMonkey uses, reducing the time it takes to compile hot code and further improving overall performance.35
Apple’s JavaScriptCore / Nitro (Safari)
JavaScriptCore (JSC) is the powerful engine that underpins Apple’s Safari browser. Its advanced optimization pipeline is often referred to by the marketing name Nitro. JSC is notable for its sophisticated four-tier execution architecture, which provides a very granular approach to balancing startup latency and runtime throughput.37
Architecture and Key Components
- Lexer & Parser: JSC uses a hand-written, recursive descent parser to process source code and build its internal syntax tree representation.37
- Low-Level Interpreter (LLInt): This is the first and fastest execution tier. The LLInt is designed for zero-cost startup (beyond parsing). It executes bytecode directly and includes basic optimizations like inline caching to ensure that even un-JITed code runs reasonably fast.29
- Baseline JIT: The second tier. The Baseline JIT compiles code for functions that are invoked a moderate number of times or contain hot loops. It compiles much faster than the optimizing JITs and also serves as the deoptimization target—when optimized code needs to bail out, it falls back to the Baseline JIT’s version.37
- DFG JIT (Data Flow Graph): The third tier is the DFG, a low-latency optimizing JIT. It uses profiling information gathered by the LLInt and Baseline JIT to build a data flow graph and perform speculative optimizations based on observed types and behaviors.37
- FTL JIT (Faster Than Light): The fourth and final tier is the FTL JIT, a high-throughput optimizing compiler. For the absolute hottest and most stable functions, JSC passes the code to the FTL JIT. This tier leverages the powerful LLVM compiler framework to perform deep, aggressive optimizations, achieving performance that can rival that of statically compiled languages like C++.37
Architectural Differences and Performance Implications
The architectures of V8, SpiderMonkey, and JavaScriptCore, while developed independently, show a clear pattern of convergent evolution. The initial problem facing all engine developers was the inherent trade-off between the fast startup of an interpreter and the high performance of an AOT compiler. A pure interpreter was too slow for complex applications, while a pure compiler introduced too much latency before a script could run.
The initial solution was a simple, two-tier JIT system: interpret first, then compile the hot code. However, empirical performance analysis revealed that the gap between “interpreted” and “highly optimized” was too vast. A function might be executed too often for the interpreter to be efficient, but not often enough to justify the significant time and memory cost of the top-tier optimizing compiler.
This realization led all three major vendors to independently develop intermediate tiers, creating the multi-tiered architectures we see today. V8 introduced Sparkplug and Maglev to fill the gap.31 JSC has long had its four-tier system with the Baseline and DFG JITs serving this purpose.37 SpiderMonkey’s Baseline JIT provides a similar intermediate step.32 This tiered approach represents the optimal solution found for the unique constraints of the web. It allows the engine to make a dynamic cost-benefit analysis for every piece of code, applying just enough compilation effort to match its observed “hotness.” This granular, adaptive strategy is the universally adopted key to high-performance execution of a dynamic language in an environment where both startup speed and runtime throughput are critical.
Comparative Analysis of Major JavaScript Engines
| Feature / Component | V8 (Google) | SpiderMonkey (Mozilla) | JavaScriptCore (Apple) |
| Primary Use Cases | Chrome, Node.js, Electron, Edge, Brave | Firefox | Safari, Bun, React Native (historically) |
| Interpreter | Ignition (Bytecode Interpreter) | Baseline Interpreter | LLInt (Low-Level Interpreter) |
| Baseline JIT Compiler | Sparkplug (Fast, non-optimizing) | Baseline JIT | Baseline JIT |
| Optimizing JIT(s) | Maglev (Mid-tier), TurboFan (Top-tier) | IonMonkey, WarpBuilder | DFG JIT (Low-latency), FTL JIT (High-throughput) |
| Key Optimization Tech | Hidden Classes (Maps), Inline Caching, Deoptimization | Type Inference, Polymorphic Inline Caches | Sophisticated tiered profiling, OSR (On-Stack Replacement) |
| Unique Characteristic | Massive ecosystem outside the browser (Node.js). Pipeline is constantly evolving with new tiers like Sparkplug and Maglev. | The oldest engine, with a publicly documented history of JIT evolution (TraceMonkey, JägerMonkey, etc.). | A four-tier architecture, culminating in the FTL JIT which leverages LLVM for deep optimization. |
Beyond the Engine: The Browser Runtime Environment
While the JavaScript engine is the core executor of code, it does not operate in isolation. To perform any meaningful action in a web browser—from changing the color of a button to fetching data from a server—the engine must interact with its surrounding environment. This broader context is known as the Browser Runtime Environment, and understanding the distinction between the engine and the runtime is fundamental to comprehending how JavaScript truly works on the web.
The Engine vs. The Runtime: A Critical Distinction
The division of labor between the JavaScript engine and the browser runtime environment is a crucial architectural concept.
- The JavaScript Engine (e.g., V8, SpiderMonkey) is the component responsible for parsing, compiling, and executing JavaScript code in strict accordance with the ECMAScript standard.4 Its world is confined to the language itself. It provides the core data structures (
Object, Array, Map), control flow mechanisms (if, for, while), and the fundamental execution model (Call Stack, Memory Heap, Garbage Collector).2 - The Runtime Environment is the “host” that embeds the engine and extends its capabilities by providing a bridge to the outside world.16 In the context of a web browser, the runtime is a vast collection of additional functionalities, often called
Web APIs, that allow JavaScript to interact with the document, the browser window, network resources, and more.
This distinction explains why common functions like console.log(), setTimeout(), and objects like document are available in browser JavaScript but are not part of the core language defined by ECMAScript.38 These are not features of the V8 engine itself; they are APIs provided by the Chrome browser runtime and exposed to the V8 engine for scripts to use.24 This modular architecture is what allows the very same V8 engine to be embedded in a completely different runtime like Node.js, which provides a different set of host APIs appropriate for a server environment, such as file system access (
fs module) and network sockets (net module), instead of browser-centric APIs like the DOM.38
Web APIs: The Browser’s Superpowers for JavaScript
Web APIs are a rich set of interfaces, typically implemented in lower-level languages like C++ within the browser’s source code, that are exposed to the JavaScript engine.41 They grant scripts the power to perform tasks far beyond simple computation.
The Document Object Model (DOM) API
The DOM is arguably the most important Web API for front-end development. It provides a structured, object-oriented representation of an HTML or XML document, modeling it as a tree of nodes.43 Every element, attribute, and piece of text in an HTML document becomes a node in this tree, which JavaScript can then access and manipulate.
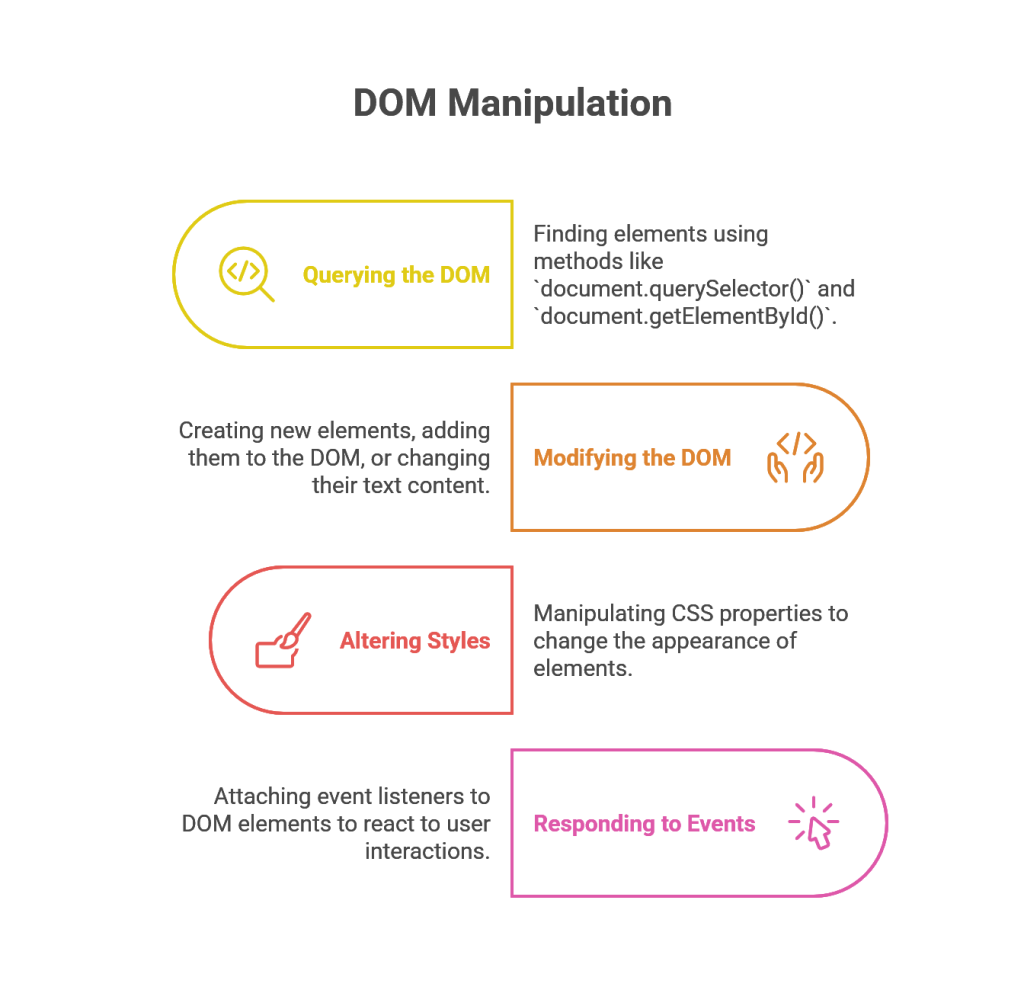
The global document object serves as the entry point to the DOM.45 Through this object, JavaScript can perform a wide range of actions:
- Querying the DOM to find elements using methods like document.querySelector() and document.getElementById().44
- Modifying the content and structure of the page by creating new elements (document.createElement()), adding them to the DOM (node.appendChild()), or changing their text content (node.textContent).45
- Altering the style of elements by manipulating their CSS properties.
- Responding to user interactions by attaching event listeners (node.addEventListener()) to DOM elements.
The DOM API is designed to be language-agnostic, but in the context of the web, it is almost exclusively controlled by JavaScript.44 It is the fundamental bridge that connects JavaScript’s logic to the visual presentation of a web page.
Timer Functions (setTimeout, setInterval)
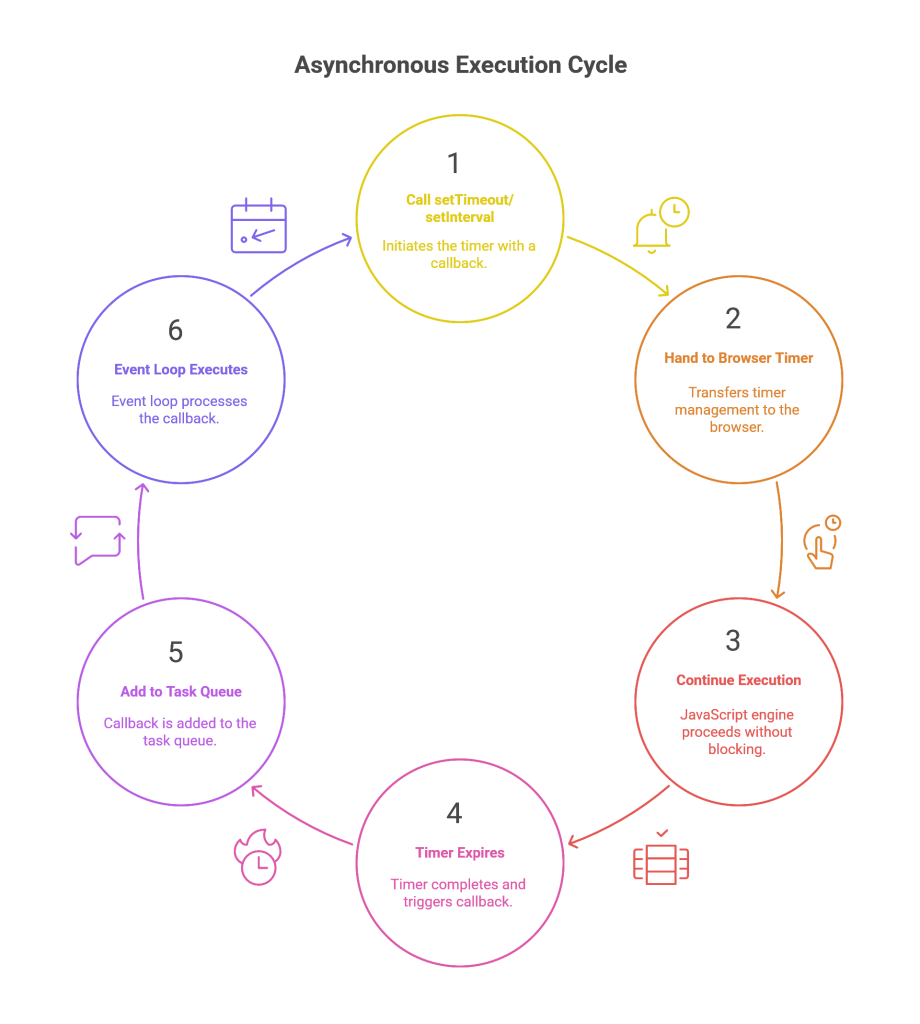
The setTimeout and setInterval functions are classic examples of Web APIs that provide asynchronous capabilities. They allow a developer to schedule a piece of code (a callback function) to be executed after a specified delay or at regular intervals, respectively.48
Crucially, these timers are not managed by the JavaScript engine’s main thread. When setTimeout(callback, 1000) is called, the engine does not pause for one second. Instead, it hands the callback function and the delay to the browser’s internal timer mechanism, which runs on a separate thread. The JavaScript engine immediately continues executing the next line of code, without blocking.48 When the timer expires, the browser runtime places the
callback function into the Task Queue, ready to be executed by the Event Loop when the Call Stack is empty.
The Fetch API for Network Requests
The Fetch API is a modern, powerful, and flexible Web API for making network requests, such as retrieving data from a server.40 It is the successor to the older
XMLHttpRequest API and is based on Promises, providing a cleaner and more robust way to handle asynchronous network operations.51
Like timers, fetch() is non-blocking. When fetch(‘https://api.example.com/data’) is called, the browser initiates the HTTP request in the background. The fetch function immediately returns a Promise object, which acts as a placeholder for the future response. The main JavaScript thread remains unblocked and can continue with other tasks. When the network response is received, the Promise is settled, and the corresponding handler functions are scheduled for execution via the Microtask Queue.
The Concurrency Model: Understanding JavaScript’s Single-Threaded Nature
The way JavaScript handles concurrency is a direct consequence of the interplay between its single-threaded engine and the multi-threaded browser runtime. JavaScript itself is strictly single-threaded: it has one Call Stack and can only execute one piece of code at a time.9 This design simplifies programming by eliminating complex issues like race conditions and deadlocks that are common in multi-threaded environments.
However, this single-threaded nature presents a significant challenge: how to perform long-running operations without freezing the application. The solution is a cooperative concurrency model. The JavaScript engine handles the synchronous, short-lived computations on its single thread. For long-running, I/O-bound tasks (like timers, network requests, or file access), the engine offloads the work to the browser’s runtime.21
The browser, being a complex application typically written in C++, is multi-threaded.20 It can handle these long-running tasks in the background on separate threads. Once a task is complete, the browser communicates the result back to the JavaScript world by placing the associated callback function into the appropriate queue (Task Queue or Microtask Queue). The Event Loop then ensures that this callback is eventually picked up and executed on the main JavaScript thread. This elegant division of labor allows a single-threaded language to achieve non-blocking, asynchronous behavior, keeping the user interface responsive even while performing complex background operations.
The Asynchronous Model and the Event Loop
The ability of JavaScript, a fundamentally single-threaded language, to handle multiple operations concurrently without freezing is one of its most powerful and often misunderstood features. This capability is not inherent to the JavaScript engine itself but is enabled by the browser’s runtime environment through a mechanism known as the Event Loop. This section deconstructs the asynchronous model, explaining why it is necessary and how the Event Loop, along with its associated queues, orchestrates non-blocking behavior.
The Problem of Synchronous Blocking
To appreciate the need for asynchronicity, one must first understand the limitations of a purely synchronous model. In synchronous programming, code is executed sequentially, one statement at a time. Each operation must complete before the next one can begin.51 While this linear execution flow is simple to reason about, it becomes a major bottleneck when a long-running task is introduced.
Consider a task like fetching a large data file from a remote server or performing a computationally intensive calculation. If such an operation were executed synchronously on JavaScript’s single main thread, it would block all other operations. In a web browser, the main thread is responsible for not only executing JavaScript but also for handling user interactions (like clicks and scrolling) and updating the user interface. A blocked main thread means the entire web page becomes unresponsive. The user would be unable to interact with any part of the page, and animations would freeze, leading to a frustrating and poor user experience.51 Asynchronous programming is the solution to this problem. It is a technique that enables a program to initiate a long-running task and remain responsive to other events while that task completes in the background.51
The Event Loop Visualized: A Step-by-Step Mechanism
The Event Loop is the heart of JavaScript’s concurrency model. It is a simple yet powerful process that continuously runs in the background, coordinating the execution of code between the Call Stack and one or more task queues.20 Its primary job is to monitor both the Call Stack and the queues. When the Call Stack is empty, the Event Loop takes the first available task from a queue and pushes it onto the Call Stack for execution.
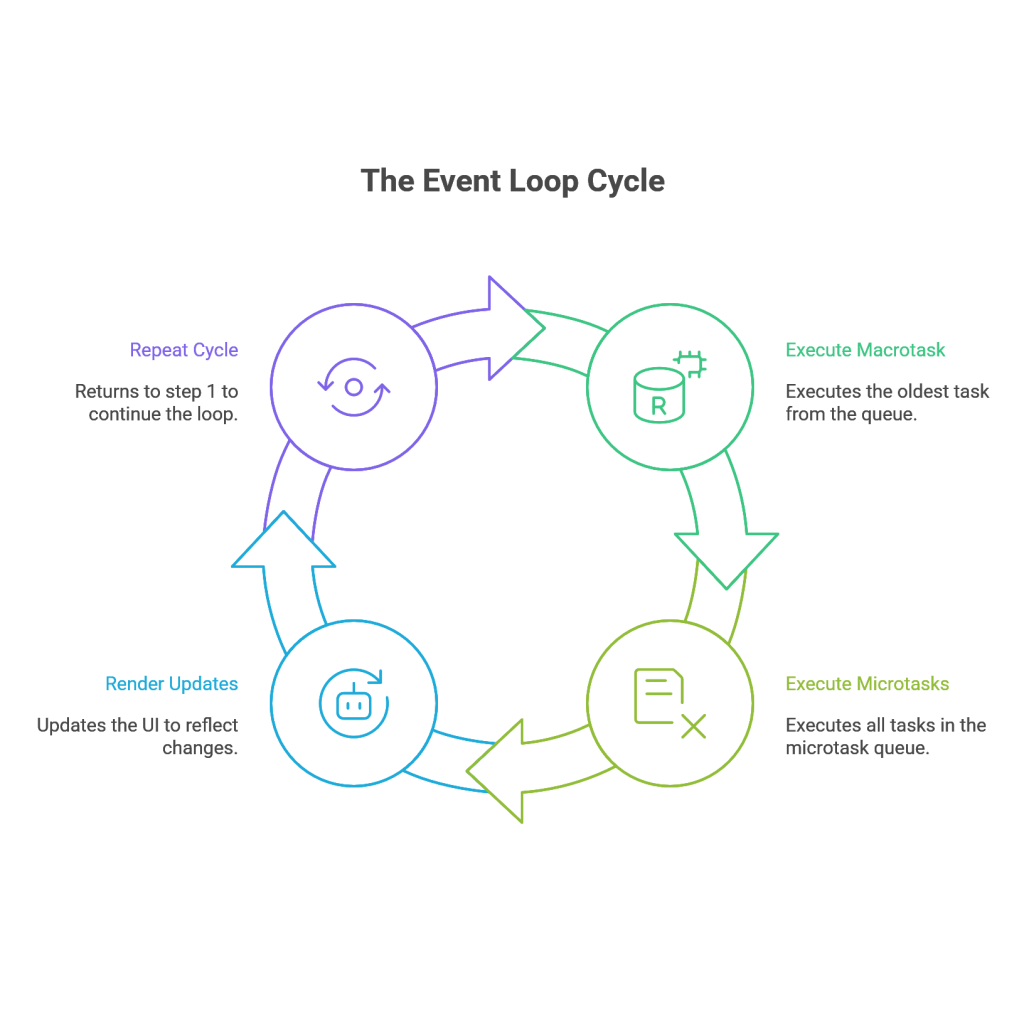
The core algorithm of the Event Loop can be broken down into a precise sequence of steps:
- Execute one Macrotask: The loop takes the oldest task from the Macrotask Queue (if one exists), pushes it onto the Call Stack, and executes it until the stack is empty again.61
- Execute all Microtasks: After the macrotask completes, the loop checks the Microtask Queue. It executes all tasks currently in the microtask queue, one by one, until the queue is completely empty. This is a critical point: if a microtask adds another microtask to the queue, that new microtask will also be executed within this same turn, before the loop proceeds.20
- Render (if necessary): After the microtask queue is empty, the browser has an opportunity to perform UI rendering updates, such as repainting the screen to reflect any DOM changes that occurred during the executed tasks.61
- Repeat: The loop then returns to step 1 to check for the next macrotask, continuing this cycle indefinitely.
Interactive tools like Loupe 64 and JSV9000 66 provide excellent visualizations of this process, making the abstract flow of tasks between the Call Stack, Web APIs, and the queues tangible and easier to understand.
The Queueing System: Macrotasks (Task Queue) vs. Microtasks
The Event Loop manages two distinct types of queues with different priorities, a design choice critical for ensuring both responsiveness and state consistency.
Macrotask Queue (or Task Queue / Callback Queue)
The Macrotask Queue (often simply called the Task Queue or Callback Queue) holds tasks that are considered to be larger, independent units of work. These tasks are handled with a lower priority than microtasks.60
- Sources of Macrotasks: Common sources include callbacks from setTimeout and setInterval, user-initiated events like click, scroll, and mousemove, I/O operations (e.g., finishing a network request or reading a file), and the initial execution of the script itself.61
- Processing: The Event Loop processes only one macrotask from the queue per iteration. After that single task is complete, the loop must yield to process the entire microtask queue before it can consider the next macrotask.61 This ensures that high-priority updates can occur between lower-priority events.
Microtask Queue
The Microtask Queue is reserved for smaller, high-priority tasks that need to be executed immediately after the current script or macrotask finishes, but before the browser performs any rendering or handles the next macrotask.63
- Sources of Microtasks: The most common sources are Promise callbacks (the functions passed to .then(), .catch(), and .finally()), the logic behind async/await, callbacks for MutationObserver (which watches for DOM changes), and tasks scheduled with the queueMicrotask() function.60
- Processing: The Microtask Queue has a higher priority than the Macrotask Queue. The Event Loop will execute every single task in the microtask queue until it is empty before moving on. This “run-to-completion” policy for microtasks ensures that a sequence of dependent asynchronous actions (like a chain of Promises) can resolve in a consistent state without being interrupted by other events.20
The existence of these two separate queues is a deliberate and sophisticated design for task scheduling. Microtasks are intended for immediate, state-consistent follow-up actions related to the current execution context. Macrotasks, on the other hand, are for scheduling new, independent, and less time-sensitive events. This prioritization is fundamental to building predictable, high-performance web applications, as it guarantees that application state is fully resolved and consistent before the browser proceeds to render changes or handle the next user interaction.
Promises and Async/Await: Taming Asynchronicity
The mechanisms for handling asynchronous operations in JavaScript have evolved to become more ergonomic and powerful, moving from raw callbacks to the more structured approach of Promises and the syntactic convenience of async/await.
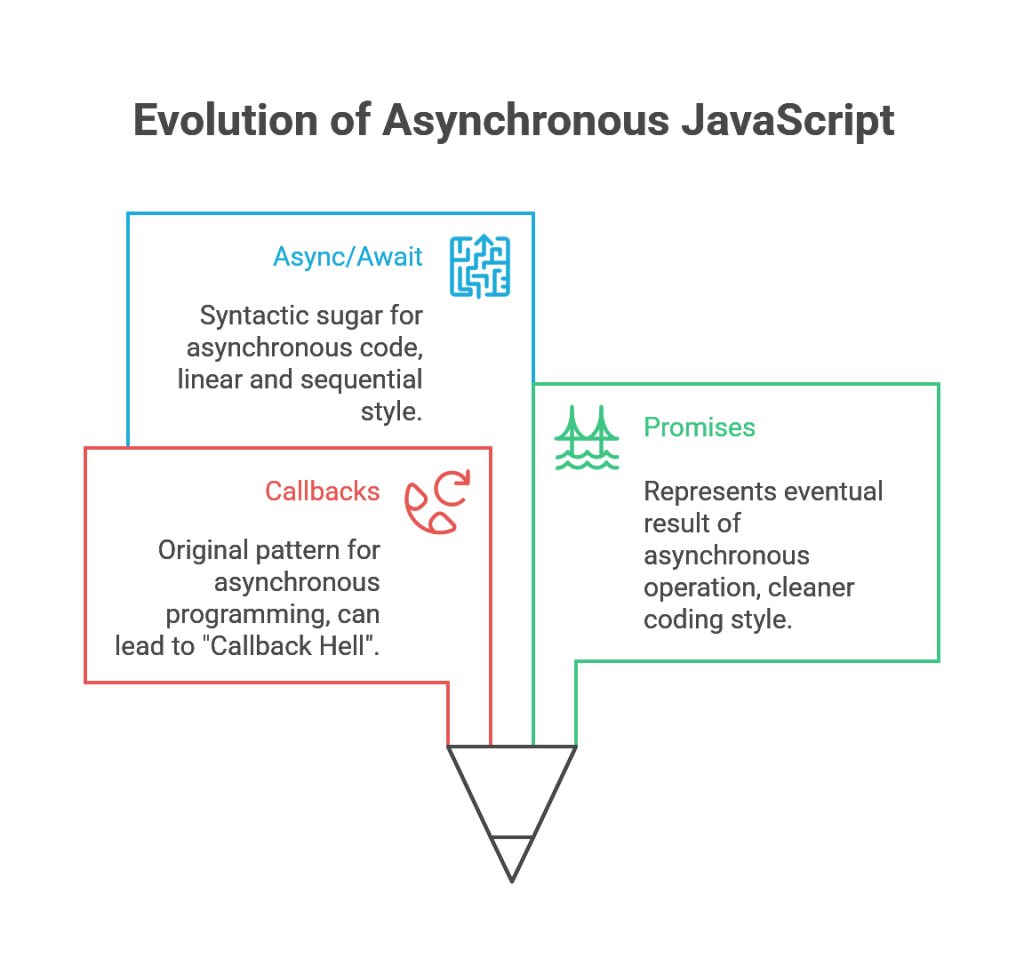
- Callbacks: This is the original pattern for asynchronous programming in JavaScript. A function is passed as an argument to an asynchronous operation, and this “callback” function is invoked when the operation completes. While functional, this pattern can lead to deeply nested and hard-to-read code when multiple asynchronous operations must be performed in sequence, a situation pejoratively known as “Callback Hell”.57
- Promises: Introduced to solve the problems of callbacks, a Promise is an object that represents the eventual result of an asynchronous operation. A Promise can be in one of three states: pending (the operation is ongoing), fulfilled (the operation completed successfully), or rejected (the operation failed).53 Promises allow for a much cleaner coding style through the chaining of
.then() methods for success cases and a centralized .catch() method for handling errors across the entire chain.53 When a Promise settles (is either fulfilled or rejected), its corresponding handler function is placed in the
Microtask Queue, ensuring it runs with high priority. - Async/Await: This is a modern feature built on top of Promises that provides syntactic sugar to make asynchronous code look and feel more like synchronous code.58 Declaring a function with the
async keyword makes it implicitly return a Promise. Inside an async function, the await keyword can be used to pause the function’s execution until a Promise settles. This allows developers to write asynchronous logic in a linear, sequential style, which is often easier to read, write, and debug than explicit Promise chains.73 Under the hood,
async/await is still powered by Promises and the Microtask Queue.
Bridging Code and Pixels: Interaction with the Rendering Engine
The execution of JavaScript does not happen in a void; it is deeply intertwined with the browser’s Rendering Engine (also known as the layout or browser engine). This component is responsible for taking the code and assets of a web page—HTML, CSS, and JavaScript—and converting them into the pixels that users see on their screen. Understanding the process by which JavaScript’s manipulation of the Document Object Model (DOM) translates into visual changes is critical for building performant and responsive web applications. This process is defined by the Critical Rendering Path.
The Critical Rendering Path (CRP): From HTML to the Screen
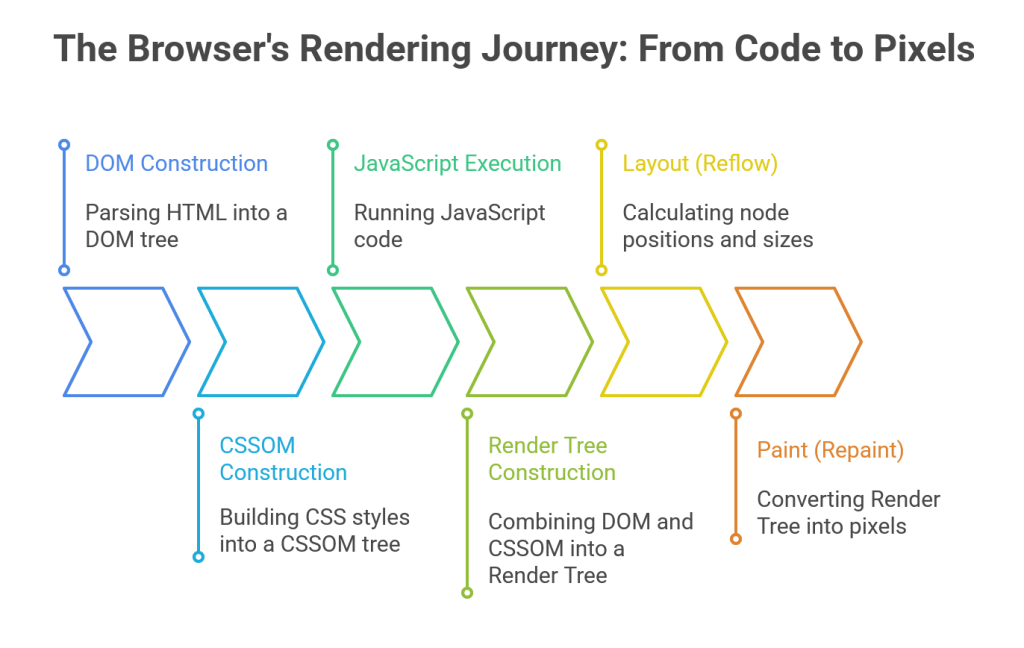
The Critical Rendering Path (CRP) is the sequence of steps the browser must perform to process the initial HTML, CSS, and JavaScript, and render the initial view of a web page.75 Optimizing this path is one of the most important aspects of web performance, as it directly impacts how quickly a user sees meaningful content. The CRP consists of several key stages:
- DOM Construction: The process begins when the browser receives the HTML document from the server. The rendering engine starts parsing the raw bytes of HTML, converting them into tokens, and then into nodes. These nodes are then assembled into a tree-like data structure called the Document Object Model (DOM). This DOM tree represents the structure and content of the HTML document. DOM construction is an incremental process; the browser can start building it as soon as the first chunks of HTML arrive.75
- CSSOM Construction: As the browser parses the HTML, it may encounter CSS, either in <style> tags or linked via <link rel=”stylesheet”> tags. It then parses this CSS to build the CSS Object Model (CSSOM), another tree-like structure that represents the styles and their relationships. Unlike DOM construction, CSSOM construction is render-blocking. The browser cannot proceed to the rendering stage until it has downloaded and parsed all CSS files. This is because CSS rules can override each other (the “Cascade”), so the browser must have the complete set of styles to accurately calculate the final appearance of each element.75
- JavaScript Execution: When the HTML parser encounters a <script> tag that is not marked with async or defer, it must pause DOM construction. The script must be downloaded, parsed, and executed immediately. This behavior makes JavaScript parser-blocking by default. The rationale is that a script might modify the DOM (for example, using document.write()), and the parser must wait to see the outcome of the script before it can safely continue building the DOM.79 This blocking behavior is a major reason why it is a best practice to place script tags at the end of the
<body> or use the async and defer attributes. - Render Tree Construction: Once the DOM and CSSOM are ready, the browser combines them to create the Render Tree. This tree contains only the nodes that are required to render the page. It captures the visible content from the DOM and the corresponding styles from the CSSOM. Nodes that are not visible—such as those in the <head> tag, elements with display: none;, or script tags—are omitted from the Render Tree.75
- Layout (Reflow): With the Render Tree constructed, the browser can now perform the Layout step (also known as Reflow). In this stage, the browser calculates the precise geometric information—the size and position—for every node in the Render Tree. It determines where each box should be placed on the screen relative to others, effectively creating a blueprint of the page’s structure.76
- Paint (Repaint): The final stage is Paint (or Repaint). The browser takes the layout information and converts the nodes in the Render Tree into actual pixels on the screen. This process, also called rasterization, involves drawing out the text, colors, images, borders, and shadows for every element, resulting in the visual representation of the page that the user sees.76
The Cost of Change: Understanding Reflow (Layout) and Repaint (Paint)
The initial rendering is just the beginning. Web pages are dynamic, and their content and appearance can change in response to user interaction or JavaScript execution. When such changes occur, the browser may need to repeat some or all of the rendering steps. These updates fall into two main categories: Reflow and Repaint.
Reflow (or Layout)
A Reflow is triggered whenever a change occurs that affects the geometry or layout of an element on the page. This is a computationally expensive operation because a change to a single element can have a cascading effect, requiring the browser to recalculate the positions and dimensions of its parent elements, child elements, and any sibling elements that follow it in the DOM.80
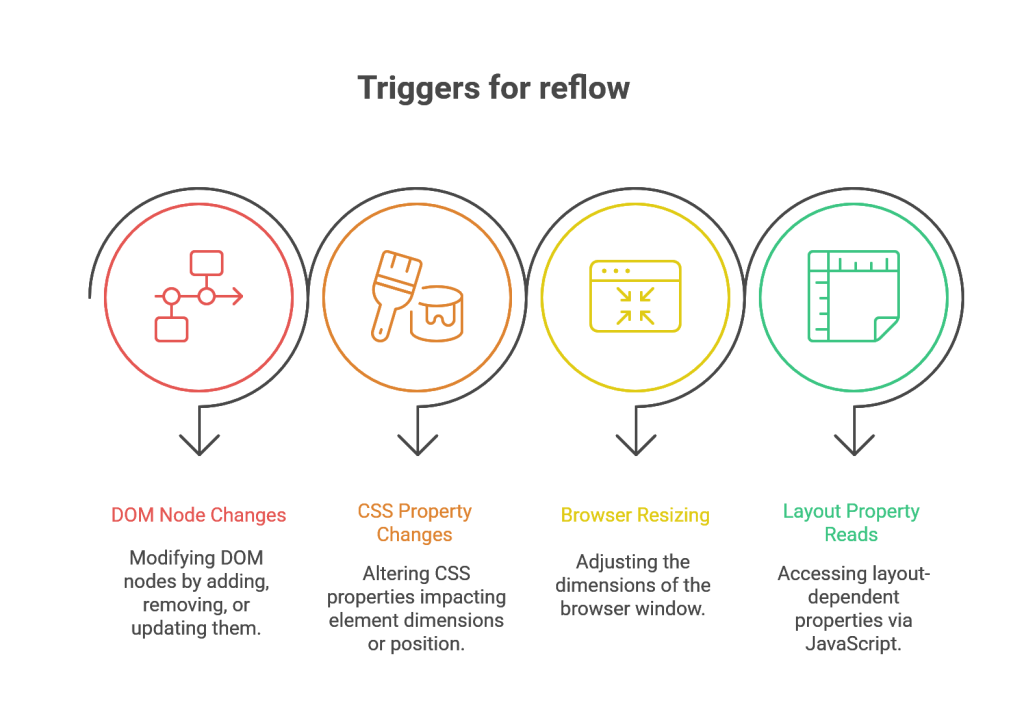
Common actions that trigger a reflow include 81:
- Adding, removing, or updating DOM nodes.
- Changing CSS properties that affect an element’s dimensions or position, such as width, height, margin, padding, border, font-size, or position.
- Resizing the browser window.
- Reading certain layout-dependent properties from JavaScript, such as element.offsetHeight, element.clientWidth, or calling element.getBoundingClientRect().
Repaint (or Paint)
A Repaint is triggered when changes are made to an element’s visual appearance, or “skin,” that do not affect its layout. This is a less expensive operation than a reflow because the browser does not need to recalculate the geometry of the page; it only needs to redraw the affected elements with their new styles.80
Common actions that trigger a repaint include 81:
- Changing visual properties like background-color, color, outline, or box-shadow.
- Changing the visibility property.
It is important to note that every reflow is always followed by a repaint, as the changes in layout must be drawn to the screen.83 However, a repaint can occur without a reflow.
How JavaScript DOM Manipulation Triggers Rendering Updates
The power of JavaScript to dynamically manipulate the DOM is also its greatest performance liability. Every time a script alters a style property that affects layout, it “invalidates” the current render tree, signaling to the browser that an update is needed.
Modern browsers are highly optimized to handle these changes efficiently. Rather than performing a reflow immediately after every single DOM modification, they typically batch these changes. The browser maintains a queue of pending style and layout changes. It will execute this queue and perform a single, consolidated reflow and repaint just before it needs to render the next frame.87
However, this optimization can be inadvertently broken by the developer. If a script first writes a style that changes the layout (e.g., element.style.width = ‘500px’;) and then immediately reads a layout-dependent property (e.g., console.log(element.offsetWidth);), it creates a performance bottleneck. To return the correct value for offsetWidth, the browser is forced to stop, flush its queue of pending changes, and perform a Forced Synchronous Layout (or Layout Thrashing). It must immediately perform a full reflow to calculate the new width before it can return the value to the script. If this read/write pattern occurs repeatedly in a loop, it can trigger dozens or even hundreds of forced reflows, severely degrading the application’s performance and causing stuttering or unresponsiveness.81
This creates a direct and critical feedback loop between JavaScript execution and the rendering pipeline. The very APIs that make the web dynamic are also the source of its most significant performance pitfalls. This means that writing performant JavaScript is not just about algorithmic efficiency (e.g., Big O notation) but also requires a deep understanding of and respect for the browser’s rendering lifecycle.
Advanced Concepts and Optimization Strategies
A comprehensive understanding of the JavaScript execution model extends beyond the core engine and rendering pipeline to include advanced topics like memory management. Mastering these concepts, coupled with practical optimization strategies, allows developers to write code that is not only functional but also highly performant and robust. The most effective optimizations are not micro-level tweaks but are strategies that demonstrate a “sympathetic” understanding of the underlying architecture of the browser and the JavaScript engine.
Memory Management and Garbage Collection in Depth
While JavaScript is a high-level, garbage-collected language that automates memory management, a foundational knowledge of how it works is essential for preventing memory leaks and writing efficient applications.12
The Memory Lifecycle
The lifecycle of memory in any application consists of three fundamental stages:
- Allocation: Memory is allocated by the engine when variables, objects, and functions are created.12
- Usage: The application reads from and writes to this allocated memory during its execution.
- Deallocation: Memory that is no longer needed is freed up, making it available for future allocations.
In JavaScript, the allocation and deallocation steps are handled automatically by the engine.90 The process of automatically reclaiming unused memory is known as
Garbage Collection (GC).
Garbage Collection (GC) and the Mark-and-Sweep Algorithm
The purpose of the garbage collector is to monitor the Memory Heap and identify objects that are no longer “reachable” by the application, and then reclaim their memory.90 All modern JavaScript engines use a sophisticated algorithm called
Mark-and-Sweep to accomplish this.12
The algorithm operates in two distinct phases:
- Mark Phase: The garbage collector starts from a set of known “root” objects. In the browser, the global window object is a primary root. The GC recursively traverses all objects that are reachable from these roots, following every reference from one object to another. Every object it visits is “marked” as being in use.12
- Sweep Phase: After the marking phase is complete, the garbage collector scans the entire heap. Any object that was not marked during the first phase is considered unreachable and is therefore “garbage.” The memory occupied by these unmarked objects is then deallocated, or “swept” away, freeing it for future use.12
Handling Cyclic References
A key advantage of the Mark-and-Sweep algorithm is its ability to correctly handle cyclic references. A cycle occurs when two or more objects reference each other, creating a closed loop (e.g., object A has a property that points to object B, and object B has a property that points back to object A).
Older, simpler garbage collection algorithms based on reference counting would fail in this scenario. Even if both objects A and B became unreachable from the root, their internal reference counts would remain non-zero, and they would never be collected, leading to a memory leak. The Mark-and-Sweep algorithm solves this problem elegantly. If the entire cycle of objects is no longer reachable from any root, none of the objects within the cycle will be marked during the mark phase. Consequently, they will all be correctly identified as garbage and collected during the sweep phase.90
Common Causes of Memory Leaks
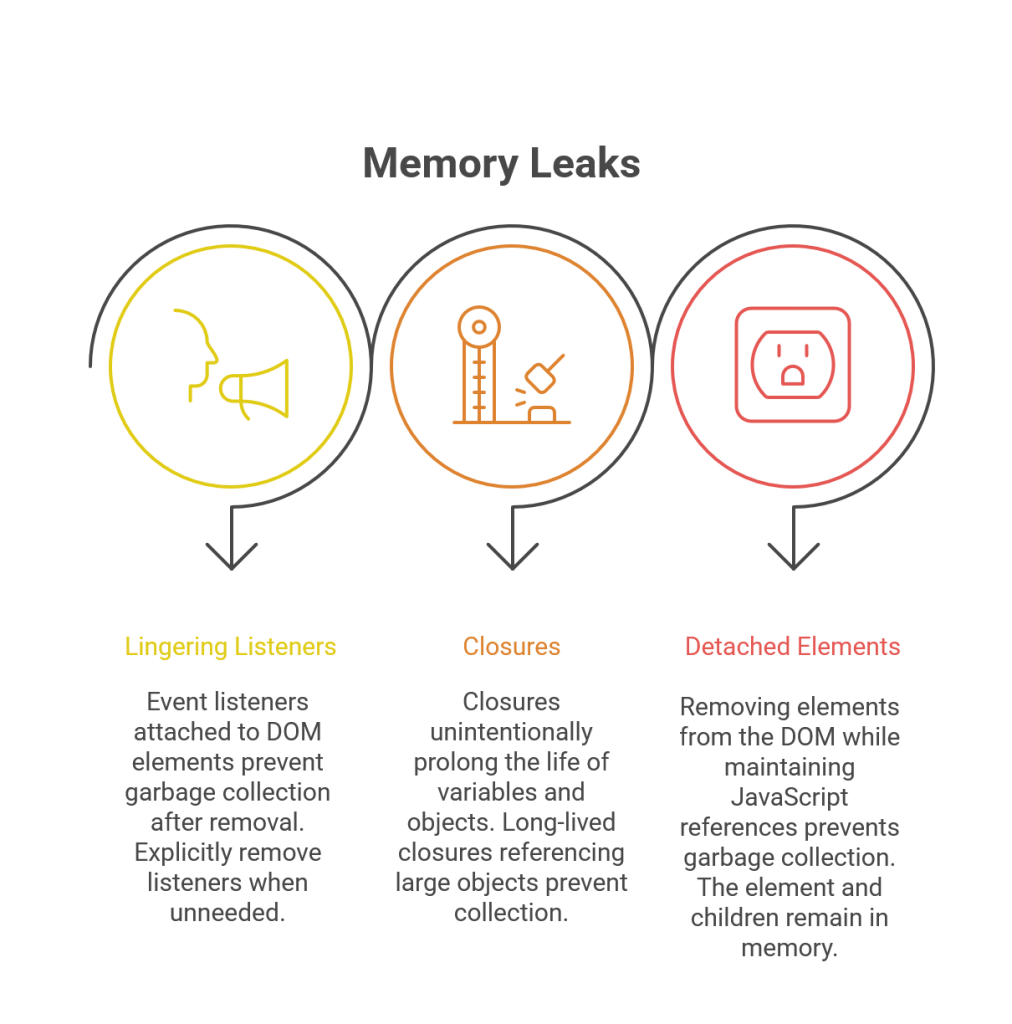
Despite the sophistication of modern garbage collectors, memory leaks can still occur in JavaScript applications. These are typically caused by developers inadvertently maintaining references to objects that are no longer needed. Common culprits include:
- Lingering Event Listeners: If an event listener is attached to a DOM element, and that element is later removed from the DOM, the listener’s closure may still hold references to variables or other objects, preventing them from being garbage collected. It is crucial to explicitly remove event listeners when they are no longer needed.
- Closures: Closures can unintentionally keep variables and objects alive longer than expected. If a long-lived closure captures a reference to a large object, that object cannot be collected until the closure itself is collected.
- Detached DOM Elements: If a script removes an element from the DOM but maintains a reference to it in a JavaScript variable, the element and all of its children will not be garbage collected.
Developers can use browser developer tools, such as the Memory tab in Chrome DevTools, to take heap snapshots, analyze memory allocation, and hunt down the source of memory leaks.12
Writing Performant Code: Practical Recommendations
The architectural principles discussed throughout this report lead directly to a set of best practices for writing high-performance JavaScript. These strategies focus on working with the browser’s systems, not against them.
Minimizing Reflows and Repaints
Since reflows are a major cause of performance degradation, minimizing them is a primary goal.
- Batch DOM Changes: Instead of manipulating the live DOM repeatedly inside a loop, perform changes on a detached element. A DocumentFragment is an excellent tool for this. A developer can append multiple new elements to a fragment in memory (which does not trigger any reflows) and then append the entire fragment to the live DOM in a single operation, causing only one reflow.82
- Avoid Layout Thrashing: Structure code to separate DOM reads from DOM writes. First, read all the necessary layout properties (e.g., offsetHeight, clientWidth) and store them in variables. Then, in a separate block of code, perform all the DOM writes (e.g., changing style properties). This prevents the browser from being forced into synchronous layouts.81
- Use CSS Classes: Instead of changing multiple individual inline styles via JavaScript (e.g., el.style.width, el.style.color, el.style.padding), define the desired state in a CSS class and then add or remove that class with a single DOM manipulation (el.classList.add(‘new-class’)). This allows the browser to handle the style changes more efficiently.84
- Animate with transform and opacity: When creating animations, prefer using CSS properties that do not trigger a reflow. The transform (for movement, scaling, rotation) and opacity properties can often be handled by the browser’s compositor on the GPU, bypassing the expensive layout and paint stages on the main thread. The will-change CSS property can also be used to give the browser a hint that an element will be animated, allowing it to perform optimizations in advance.82
Avoiding JIT Deoptimization
To help the JIT compiler produce and maintain fast, optimized machine code, developers should strive to write predictable, type-stable code.
- Maintain Consistent Object Shapes: Avoid adding or deleting properties from objects after they have been created. Initialize objects with a consistent structure.
- Pass Consistent Types to Functions: Try to ensure that a function is always called with arguments of the same type. This helps the engine’s inline caches remain in a fast, monomorphic state and prevents the performance penalty associated with polymorphism and the costly process of deoptimization.30
Leveraging Asynchronous Patterns Effectively
- Prefer async/await for Readability: While it is syntactic sugar, async/await makes complex asynchronous flows much easier to reason about than nested callbacks or long promise chains.
- Use Promise.all for Concurrency: When you have multiple independent asynchronous operations that need to complete, do not await them sequentially. This would execute them one after another. Instead, initiate them all at once and use Promise.all to wait for all of them to complete. This allows the operations to run concurrently, significantly reducing the total wait time.72
- Be Mindful of Microtask Queuing: Remember that promise handlers are executed as microtasks. Creating an infinitely recursive chain of microtasks (e.g., a promise handler that schedules another promise handler) can block the event loop from ever processing macrotasks (like user input) or rendering the UI, making the page unresponsive.
Conclusion
The inner workings of JavaScript within a web browser reveal a sophisticated and symbiotic ecosystem, far more complex than a simple script interpreter. The execution of even a single line of code is the result of an intricate dance between multiple highly optimized systems: the JavaScript Engine, the Browser Runtime Environment, and the Rendering Engine.
The journey begins in the JavaScript Engine, where source code is parsed into an Abstract Syntax Tree, compiled into bytecode by an interpreter like V8’s Ignition, and then dynamically optimized into native machine code by a Just-In-Time compiler like TurboFan. This multi-tiered compilation strategy is a masterful compromise, balancing the need for rapid script startup with the demand for high-performance execution of complex application logic. The engine’s foundational memory model, composed of the methodical Call Stack for function execution and the dynamic Memory Heap for object storage, is managed automatically by a garbage collector employing an efficient Mark-and-Sweep algorithm.
However, the engine is a pure language executor, confined by the ECMAScript standard. Its true power is unlocked by the Browser Runtime Environment, which provides a rich set of Web APIs. These APIs act as a bridge, allowing the single-threaded engine to interact with the multi-threaded browser and the outside world. The DOM API enables dynamic manipulation of page content, while asynchronous APIs like setTimeout and fetch offload long-running tasks, preventing the main thread from blocking.
This cooperative relationship is orchestrated by the Event Loop, the heart of JavaScript’s concurrency model. By managing a high-priority Microtask Queue for immediate, state-sensitive updates from Promises and a lower-priority Macrotask Queue for user events and other callbacks, the event loop ensures that a single-threaded language can achieve non-blocking, responsive behavior.
Finally, the execution of JavaScript is inextricably linked to the visual output produced by the Rendering Engine. JavaScript’s ability to manipulate the DOM triggers the Critical Rendering Path, a sequence of steps including Layout (Reflow) and Paint that translate the document’s structure and style into pixels on the screen. This direct control is a double-edged sword; while it enables dynamic user interfaces, it also introduces significant performance pitfalls like Layout Thrashing, where inefficient code can force the browser into costly, synchronous rendering updates.
Ultimately, a deep architectural understanding of this entire process empowers developers to transcend writing merely functional code. By crafting code that is “sympathetic” to the underlying systems—by minimizing reflows, maintaining type stability for the JIT compiler, managing memory references carefully, and leveraging asynchronous patterns correctly—developers can work in harmony with the browser’s design. This knowledge is the key to building the efficient, robust, and fluidly responsive web applications that modern users expect.
References
- developer.mozilla.org, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Glossary/Engine/JavaScript#:~:text=JavaScript%20engines%20are%20interpreters%20that,executed%20by%20a%20computer’s%20processor.
- JavaScript Engine and Runtime Explained – freeCodeCamp, accessed July 22, 2025, https://www.freecodecamp.org/news/javascript-engine-and-runtime-explained/
- Engine – Glossary – MDN Web Docs – Mozilla, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Glossary/Engine
- JavaScript engine – Glossary – MDN Web Docs, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Glossary/Engine/JavaScript
- ELI5: What is a JavaScript Engine? Is it just a some sort of compiler/interpreter in a browser? : r/webdev – Reddit, accessed July 22, 2025, https://www.reddit.com/r/webdev/comments/4cgrpf/eli5_what_is_a_javascript_engine_is_it_just_a/
- Browser Architecture and In-depth understanding of the Javascript V8 engine | by Indrajit V, accessed July 22, 2025, https://medium.com/@vindrajit1996/how-does-javascript-v8-engine-works-8756648e592f
- How JavaScript Works: Under the Hood of the V8 Engine – freeCodeCamp, accessed July 22, 2025, https://www.freecodecamp.org/news/javascript-under-the-hood-v8/
- JavaScript – MDN Web Docs – Mozilla, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/JavaScript
- Javascript Fundamentals — Call Stack and Memory Heap | by Allan …, accessed July 22, 2025, https://medium.com/@allansendagi/javascript-fundamentals-call-stack-and-memory-heap-401eb8713204
- Discuss the execution engine in javascript – crio community, accessed July 22, 2025, https://forum-external.crio.do/t/discuss-the-execution-engine-in-javascript/243
- Confusion between stack, call stack and memory heap in Javascript – Stack Overflow, accessed July 22, 2025, https://stackoverflow.com/questions/72760109/confusion-between-stack-call-stack-and-memory-heap-in-javascript
- Memory Management in JavaScript – GeeksforGeeks, accessed July 22, 2025, https://www.geeksforgeeks.org/javascript/memory-management-in-javascript/
- JavaScript Engine: Call Stack and Memory Heap – Medium, accessed July 22, 2025, https://medium.com/@atuljha2402/inside-the-javascript-engine-exploring-the-call-stack-and-memory-heap-fe6f34c82a7?responsesOpen=true&sortBy=REVERSE_CHRON
- Javascript Engine and Call Stack explained – DEV Community, accessed July 22, 2025, https://dev.to/mcwiise/javascript-engine-and-call-stack-explained-20l0
- Understanding Execution Context and Execution Stack in Javascript – Bits and Pieces, accessed July 22, 2025, https://blog.bitsrc.io/understanding-execution-context-and-execution-stack-in-javascript-1c9ea8642dd0
- JavaScript execution model – MDN Web Docs, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Execution_model
- The Ultimate Guide to Hoisting, Scopes, and Closures in JavaScript, accessed July 22, 2025, https://ui.dev/ultimate-guide-to-execution-contexts-hoisting-scopes-and-closures-in-javascript
- All you need to learn to understand JavaScript _ Execution Context and Stack, accessed July 22, 2025, https://nazdelam.medium.com/all-you-need-to-learn-to-understand-javascript-execution-context-and-stack-3babbdd88868
- Global object – Glossary – MDN Web Docs – Mozilla, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Glossary/Global_object
- In depth: Microtasks and the JavaScript runtime environment – Web APIs | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/HTML_DOM_API/Microtask_guide/In_depth
- Understanding Memory Heap & Memory Leaks – How the JS Engine Works – Part 1/6, accessed July 22, 2025, https://frontendly.io/blog/js-engine-memory-heap-part-1
- What is Call Stack in JavaScript? Devlane, accessed July 22, 2025, https://www.devlane.com/blog/what-is-call-stack-in-javascript
- Awesome-JavaScript-Interviews/Javascript/call-stack-good-example.md at master – GitHub, accessed July 22, 2025, https://github.com/rohan-paul/Awesome-JavaScript-Interviews/blob/master/Javascript/call-stack-good-example.md
- JavaScript, JavaScript Engine, Runtime environment – Kirti Lulle’s blog, accessed July 22, 2025, https://kirtiblog.hashnode.dev/how-javascript-engine-works
- I want to understand what is JIT compilers and how do they work. : r/learnjavascript – Reddit, accessed July 22, 2025, https://www.reddit.com/r/learnjavascript/comments/1b73q53/i_want_to_understand_what_is_jit_compilers_and/
- The V8 Engine Series I: Architecture | by Mahmoud Yasser – Medium, accessed July 22, 2025, https://braineanear.medium.com/the-v8-engine-series-i-architecture-ba08a38c54fa
- Internals of Google’s V8 JS Engine – Ansi ByteCode LLP, accessed July 22, 2025, https://ansibytecode.com/internals-of-googles-v8-js-engine/
- How V8 compiles JavaScript code ? – GeeksforGeeks, accessed July 22, 2025, https://www.geeksforgeeks.org/how-v8-compiles-javascript-code/
- Java Script Engine(How JS Works Behind The Scenes The Engine) – DEV Community, accessed July 22, 2025, https://dev.to/ahmed_niazy/java-script-engine-2gcj
- Understanding Just-In-Time (JIT) Compilation in V8: A … – Medium, accessed July 22, 2025, https://medium.com/@rahul.jindal57/understanding-just-in-time-jit-compilation-in-v8-a-deep-dive-c98b09c6bf0c
- V8 (JavaScript engine) – Wikipedia, accessed July 22, 2025, https://en.wikipedia.org/wiki/V8_(JavaScript_engine)
- How SpiderMonkey works in Mozilla Firefox Browser? – GeeksforGeeks, accessed July 22, 2025, https://www.geeksforgeeks.org/websites-apps/how-spidermonkey-works-in-mozilla-firefox-browser/
- SpiderMonkey Byte-sized Architectures, accessed July 22, 2025, https://spidermonkey.dev/assets/pdf/SpiderMonkey%20Byte-sized%20Architectures.pdf
- SpiderMonkey Internals, accessed July 22, 2025, https://udn.realityripple.com/docs/Mozilla/Projects/SpiderMonkey/Internals
- SpiderMonkey – Wikipedia, accessed July 22, 2025, https://en.wikipedia.org/wiki/SpiderMonkey
- Understanding JavaScript Engine Internals: V8, SpiderMonkey, and More – DEV Community, accessed July 22, 2025, https://dev.to/shruti_kumbhar/understanding-javascript-engine-internals-v8-spidermonkey-and-more-2f0m
- JavaScriptCore – WebKit Documentation, accessed July 22, 2025, https://docs.webkit.org/Deep%20Dive/JSC/JavaScriptCore.html
- What is the difference between JavaScript Engine and JavaScript Runtime Environment, accessed July 22, 2025, https://stackoverflow.com/questions/29027845/what-is-the-difference-between-javascript-engine-and-javascript-runtime-environm
- Difference/gap between Javascript engine and runtime? : r/learnjavascript – Reddit, accessed July 22, 2025, https://www.reddit.com/r/learnjavascript/comments/1eno1wu/differencegap_between_javascript_engine_and/
- Web APIs for JavaScript – Antistatique, accessed July 22, 2025, https://antistatique.net/en/blog/web-apis-for-javascript
- All all Web API interfaces actually JavaScript objects? : r/learnjavascript – Reddit, accessed July 22, 2025, https://www.reddit.com/r/learnjavascript/comments/18dluqs/all_all_web_api_interfaces_actually_javascript/
- Client-side web APIs – Learn web development | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Learn_web_development/Extensions/Client-side_APIs
- DOM (Document Object Model) – Glossary – MDN Web Docs, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Glossary/DOM
- Introduction to the DOM – Web APIs | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction
- Using the Document Object Model – Web APIs – MDN Web Docs, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Using_the_Document_Object_Model
- Document – Web APIs | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/Document
- DOM scripting introduction – Learn web development | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Scripting/DOM_scripting
- Window: setTimeout() method – Web APIs | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/Window/setTimeout
- Window: setInterval() method – Web APIs – MDN Web Docs – Mozilla, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/Window/setInterval
- How to use the setTimeout() function in JavaScript – Muse, accessed July 22, 2025, https://airdward.hashnode.dev/how-to-use-the-settimeout-function-in-javascript
- Introducing asynchronous JavaScript – Learn web development | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Learn_web_development/Extensions/Async_JS/Introducing
- Fetch API – Web APIs | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API
- How to use promises – Learn web development | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Learn_web_development/Extensions/Async_JS/Promises
- Synchronous and Asynchronous in JavaScript – GeeksforGeeks, accessed July 22, 2025, https://www.geeksforgeeks.org/javascript/synchronous-and-asynchronous-in-javascript/
- JavaScript Visualized: Event Loop – DEV Community, accessed July 22, 2025, https://dev.to/lydiahallie/javascript-visualized-event-loop-3dif
- Role of JavaScript engines in browser architecture | by The Educative Team, accessed July 22, 2025, https://learningdaily.dev/role-of-javascript-engines-in-browser-architecture-ba63c3dceb05
- How Asynchronous JavaScript Works – freeCodeCamp, accessed July 22, 2025, https://www.freecodecamp.org/news/asynchronous-javascript/
- Asynchronous Programming in JavaScript – Guide for Beginners, accessed July 22, 2025, https://www.freecodecamp.org/news/asynchronous-programming-in-javascript/
- JavaScript Event Loop: A Visual Explanation – Latenode community, accessed July 22, 2025, https://community.latenode.com/t/javascript-event-loop-a-visual-explanation/8257
- The JavaScript Event Loop Explained with Examples | by Dzmitry Ihnatovich – Medium, accessed July 22, 2025, https://medium.com/@ignatovich.dm/the-javascript-event-loop-explained-with-examples-d8f7ddf0861d
- Event loop: microtasks and macrotasks, accessed July 22, 2025, https://javascript.info/event-loop
- Difference between microtask and macrotask within an event loop context – Stack Overflow, accessed July 22, 2025, https://stackoverflow.com/questions/25915634/difference-between-microtask-and-macrotask-within-an-event-loop-context
- Understanding the Event Loop, the Task Queue, and the Microtask Queue in JavaScript – Lual Dev, accessed July 22, 2025, https://lual.dev/blog/understanding-the-event-loop-in-javascript/
- Loupe – Philip Roberts, accessed July 22, 2025, http://latentflip.com/loupe/
- Amazing tool for visualizing JavaScript’s call stack/event loop/callback queue – Reddit, accessed July 22, 2025, https://www.reddit.com/r/learnprogramming/comments/61gq9f/amazing_tool_for_visualizing_javascripts_call/
- JS Visualizer 9000, accessed July 22, 2025, https://www.jsv9000.app/
- Microtask Queue, Macrotask Queue, and Rendering Queue – GitHub, accessed July 22, 2025, https://github.com/imdeepmind/imdeepmind.github.io/blob/main/docs/programming-languages/javascript/queues.md
- Event loop in JavaScript, microtask, macrotask, Promise, and common interview questions, accessed July 22, 2025, https://levelup.gitconnected.com/event-loop-in-javascript-microtask-macrotask-promise-and-common-interview-questions-14b7ee57be94
- How the Event Loop Handles Microtasks and Macrotasks – DEV …, accessed July 22, 2025, https://dev.to/dinhkhai0201/how-the-event-loop-handles-microtasks-and-macrotasks-4hi7
- Difference Between Microtask Queue and Callback Queue in asynchronous JavaScript – GeeksforGeeks, accessed July 22, 2025, https://www.geeksforgeeks.org/javascript/what-is-the-difference-between-microtask-queue-and-callback-queue-in-asynchronous-javascript/
- dev.to, accessed July 22, 2025, https://dev.to/dinhkhai0201/how-the-event-loop-handles-microtasks-and-macrotasks-4hi7#:~:text=The%20microtask%20queue%20has%20a,on%20to%20the%20next%20macrotask.
- Asynchronous Programming :: Eloquent JavaScript, accessed July 22, 2025, https://eloquentjavascript.net/11_async.html
- async function – JavaScript – MDN Web Docs – Mozilla, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/async_function
- Can you please explain to me async and await in a simplified way? Very confusing concept I would love someone to explain it clearly . : r/react – Reddit, accessed July 22, 2025, https://www.reddit.com/r/react/comments/u8omtk/can_you_please_explain_to_me_async_and_await_in_a/
- Critical rendering path – Performance | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/Performance/Guides/Critical_rendering_path
- Critical Rendering Path: What It Is and How to Optimize It – NitroPack, accessed July 22, 2025, https://nitropack.io/blog/post/critical-rendering-path-optimization
- Inside the Critical Rendering Path: What Your Browser Is Really Doing – DEV Community, accessed July 22, 2025, https://dev.to/abhinavshinoy90/inside-the-critical-rendering-path-what-your-browser-is-really-doing-15mp
- Understanding Critical Rendering Path (CRP) – Bits and Pieces, accessed July 22, 2025, https://blog.bitsrc.io/understanding-critical-rendering-path-crp-c0a240bfcdce
- Understand the critical path | web.dev, accessed July 22, 2025, https://web.dev/learn/performance/understanding-the-critical-path
- What are Reflow and Repaint? How to optimize? – ExplainThis, accessed July 22, 2025, https://www.explainthis.io/en/swe/repaint-and-reflow
- DOM Performance (Reflow & Repaint) (Summary) – GitHub Gist, accessed July 22, 2025, https://gist.github.com/faressoft/36cdd64faae21ed22948b458e6bf04d5
- Repaint and Reflow of DOM and optimization techniques | by Shaharyar – Medium, accessed July 22, 2025, https://shaharyarshamshi.medium.com/repaint-and-reflow-of-dom-and-optimization-techniques-3b75da72f05f
- What’s the difference between reflow and repaint? – Stack Overflow, accessed July 22, 2025, https://stackoverflow.com/questions/2549296/whats-the-difference-between-reflow-and-repaint
- Reflows and Repaints in Javascript – DEV Community, accessed July 22, 2025, https://dev.to/jharna_khatun/reflows-and-repaints-in-javascript-2ep1
- Minimizing browser reflow | PageSpeed Insights | Google for …, accessed July 22, 2025, https://developers.google.com/speed/docs/insights/browser-reflow
- what is reflow & repaint in the browser? And how they affect performance (DOM, CSSOM, Render tree) – YouTube, accessed July 22, 2025, https://www.youtube.com/watch?v=PK4bzxWLOfo
- When exactly does the browser repaint and reflow? – Stack Overflow, accessed July 22, 2025, https://stackoverflow.com/questions/73736185/when-exactly-does-the-browser-repaint-and-reflow
- Avoid Reflow & Repaint – Blog : Hi Interactive, accessed July 22, 2025, https://www.hi-interactive.com/blog/avoid-reflow-repaint
- Should JavaScript be able to control reflow? – Reddit, accessed July 22, 2025, https://www.reddit.com/r/javascript/comments/ljm7p/should_javascript_be_able_to_control_reflow/
- Memory management – JavaScript | MDN, accessed July 22, 2025, https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Memory_management
- Understanding Mark and Sweep Algorithm in JavaScript – Stack Overflow, accessed July 22, 2025, https://stackoverflow.com/questions/60354194/understanding-mark-and-sweep-algorithm-in-javascript
- Mark and Sweep Algorithm in JavaScript – Perficient Blogs, accessed July 22, 2025, https://blogs.perficient.com/2024/12/16/insight-on-mark-and-sweep-algorithm/
- Avoiding Common Web Performance Pitfalls: Reducing Reflow and Redraw | by Brandon Evans | JavaScript in Plain English, accessed July 22, 2025, https://javascript.plainenglish.io/avoiding-common-web-performance-pitfalls-reducing-reflow-and-redraw-c95ae77af9b4